Configuring Pavilion¶
Pavilion is driven largely by configurations. This documentation page covers
the pavilion.yaml file, which sets global pavilion settings.
See Test Format for information on the other types of pavilion configuration.
This documentation only covers a few important settings. For a full list
of settings, use the pav show config --template command, which will give
the full docs.
Contents
Config Directories¶
Pavilion looks its main pavilion.yaml config in the following hierarchy
and uses the first one it finds.
- The user’s ~/.pavilion directory.
- The directory given via the
PAV_CONFIG_DIRenvironment variable. - The Pavilion lib directory (don’t put configs here)
The pavilion.yaml file can configure additional locations to look for test,
mode, and host configs, as well as plugins using the config_dirs option.
The ~/.pavilion directory is only searched for pavilion.yaml by
default, but searches for other configs there can be turned on in pavilion
.yaml
Each config directory can (optionally) have any of the sub-directories shown here.
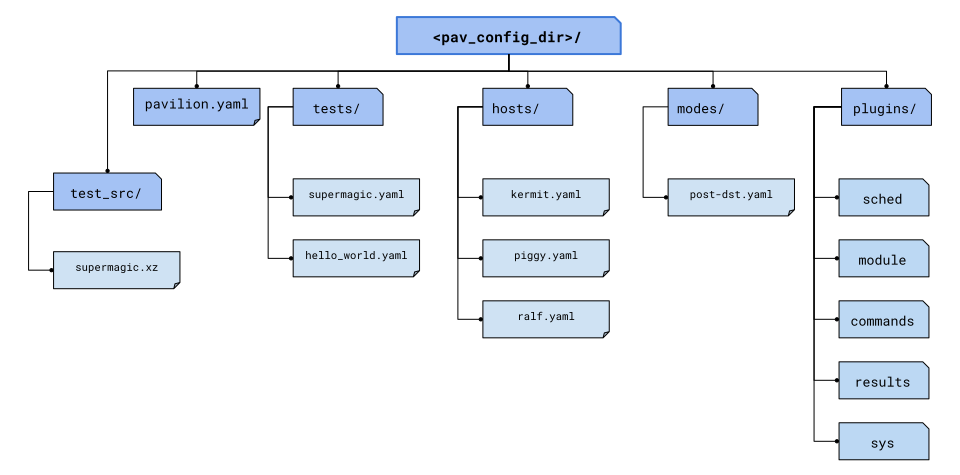
Config Directory Layout
It’s ok to run pavilion without a pavilion.yaml; the defaults should
be good enough in many cases.
Generating a pavilion.yaml template¶
Pavilion can print template files, with documentation, for all of it’s
config files. In this case, use the command pav show config --template.
Since this file is self documenting, refer to
it for more information about each of the configuration settings.
Setting You Should Set¶
While everything has a workable default, you’ll probably want to set the following.
working_dir¶
This determines where your test run information is stored. If you don’t
set this, everyone will have a separate history in
$HOME/.pavilion/working_dir.
result_log¶
The result log holds all the result json for every test you run. If you want to feed that into splunk, you may want to specify where to write it.
flatten_results¶
When writing results to the result log, create a separate entry for each
item under the per_file key in results. Each such entry is merged into
base results, and the name of the per_file entry is added under the “file”
key. This is useful for applications like Splunk, which expect
separate log entries for each distinct item.
{"name": "test1", "avg_speed": 32.5,
per_file: {"node1": {"speed": 32}, "node2": {"speed": 33}}}
This would be logged in the central results log as:
{"name": "test1", "avg_speed": 32.5, "file": "node1", "speed": 32}
{"name": "test1", "avg_speed": 32.5, "file": "node2", "speed": 33}
This does not change how logs are written to the per-test-run results file.